
During the course Advanced Computer Graphics and Applications I had lots of time (and freedom!) to develop something interesting. While this is an article about computer graphics, it’s also about high-performance parallelization strategies.
I have written a GPU-Driven forward rendering using clustered shading. It can render 27’000 Stanford dragons with 10’000 lights at 1080p in over 60fps on a GTX 1070 GPU. In this post, I will present exactly how my renderer achieves this performance.

GPU-Driven What?
In a conventional renderer, there is a certain kind of separation in memory and ownership between the GPU and CPU. Usually, the GPU owns texture data, meshes, and other assets—while the CPU owns entity data (position, velocity, etc.). This is usually a good design, as the entity data is modified many times on the CPU and uploaded once (through a uniform or similar) for each frame to the GPU.
This however, means that certain barriers need to be put up between writing the per-object data and rendering it. Importantly, using a single uniform for all objects requires that each object is rendered sequentially in it’s own draw call.
Our goal is to reduce the number of draw calls to as few as possible. In both GL and Vulkan, draw calls can be issued as indirect multi draws. These differ from normal draw calls in that the CPU dispatches the instruction with the draw details (index count, start vertex index) already present on the GPU in a buffer. This way, a single API call can execute multiple draw calls. It results in a few limitations —for example, re-binding resources or changing shaders between draw calls is not possible—but is a tradeoff for performance.
And just let me be clear. This is not instancing! Using a single mesh in my example is a bit unfortunate, as indirect rendering supports rendering different meshes. Well technically, you can render multiple different meshes using instanced draw calls (with some hacks), but instancing cannot control what you draw from the GPU.
In my renderer, the entity (object) data is kept in a contiguous buffer, and any modifications to it are marked. Before rendering a frame, all modified parts are uploaded to the GPU.
Memory
In the above figure, the GPU buffers used are shown. As some other renderers do, we share a single GPU buffer for all vertex data, and use a simple allocator which manages this contiguous buffer automatically. This is done for the index buffer as well. There is a drawback to doing this; it requires all vertices to have the same format (same attributes). This can be a problem if there are many different types of meshes in a scene. One solution can be to have a separate vertex buffers for some attributes, which may also improve performance due to cache coherency. For example, one might want to make a separate buffer for animated vertices, or a separate buffer for only the animation attributes (bone ids, weights, etc.).
We also have some unique buffers to this system; namely, the Object Buffer and the Draw Buffer. These contains information that a conventional CPU-driven renderer must provide to the GPU every frame, but are instead stored on device. Objects that are fully static (terrain for example) only needs to be uploaded once. The draw buffer is what actually reduces the number of CPU draw calls (using the aforementioned draw indirect API).
Draw Call Generation
For an optimized renderer, we want to cull objects that are outside the main camera frustum. As you can see from the buffer diagram, we actually have everything we need (except for the camera) to determine what needs to be rendered. As we now create draw calls (into the Draw Buffer) from the GPU, the GPU is now able to cull the scene, which should come with significant speed improvements.
I simplified this by having the meshes store an axis-aligned bounding box (AABB). While other shapes could be used (just prepend a flag), this works well in my cases.
Using a compute shader, elements in the draw buffer are created from each object
if that object is visible. A simple implementation is inserting at the same
index as the original object definition is in. This means that the culling can
be extremely parallelized where each thread of a subgroup culls a single
object. One drawback with this design is that the final draw buffer becomes sparse;
and therefore requiring more memory than necessary. If we assume that sometimes
all objects are visible, this would be fine as we need a buffer that large.
But usually, games might cull as much as 70% or more of the number of objects.
A developer runs the game and sees that no more than 50% of all objects are
shown in a single frame, meaning that the draw buffer could be as small as 50%
of the object buffer. Also, we can expect performance improvements (assuming that
compaction is quick) as the draw elements will improve spacial locality. Another
thing to consider is that NOP draw indirect calls (that is, calls with 0 vertices),
are actually not free, so we can also expect the draw to become quicker.
Running on my GTX 1070, I get a 2.97ms overhead of rendering 125k objects all being culled (avg. 23ns per object).
Special care needs to be taken to support multiple shaders. While I didn’t need it, I tried implementing it but met only issues. The problem is that each shader must be assigned an estimation of the number of objects that can be drawn with that shader. Either, you store both draw lists in the same buffer (reserve 70% to shader A, 30% to shader B), or you create 2 different buffers.
Compaction
To support this, we want to compact the elements inserted into the draw buffer such that they reside contiguously. This is actually pretty simple to implement using an atomic counter. On the start of each frame, the counter gets reset to zero. For every object which will require rendering, the atomic counter is incremented. Draws are inserted on the index given by the atomic counter.
Simple, yes! Performant? Meh. Well, it is actually pretty simple to optimize this as well. GPU programming is interesting as similar to SIMD-instructions, the most efficient usage comes with great consideration of cooperation. In this case we will use subgroup operation using ballots to speed up cluster compaction.
Ballots are simply a bitset where each thread in the subgroup has ownership of it. For example, each thread can evaluate a boolean and then assign it to their slot in the bitset. It also has cheap operations for evaluating over the whole ballot, like addition, bit count, and more.
I find this algorithm hard to explain, so below I provide both my code and a diagram explaining it.
void main() {
uint idx = gl_GlobalInvocationID.x;
uint local_id = gl_LocalInvocationID.x;
uint object_id = idx;
uint mesh_id = objects[object_id].mesh_id;
// Skip invalid objects (those with no geometry)
if (mesh_id == -1) return;
mat4 affine_transform = unpack_affine_transform(object_id);
bool visible = is_visible(object_id, affine_transform);
uvec4 valid_mask = subgroupBallot(visible);
uint local_offset = subgroupBallotExclusiveBitCount(valid_mask);
uint local_count = subgroupBallotBitCount(valid_mask);
uint base_offset = 0;
if (subgroupElect()) {
base_offset = atomicAdd(draw_count, local_count);
}
base_offset = subgroupBroadcastFirst(base_offset);
if (visible) {
uint lod = get_lod(object_id, affine_transform);
uint draw_idx = base_offset + local_offset;
uint index_count = meshes[mesh_id].lods[lod].index_count;
uint index_start = meshes[mesh_id].lods[lod].index_start;
emitDraw(draw_idx, index_count, index_start, object_id);
atomicAdd(stats.draw_count, 1);
atomicAdd(stats.draw_count_lod[lod], 1);
}
}
After using this algorithm, the overhead of drawing 125k culled objects shrank to a static cost of 0.9ms (being the single empty draw indirect call).
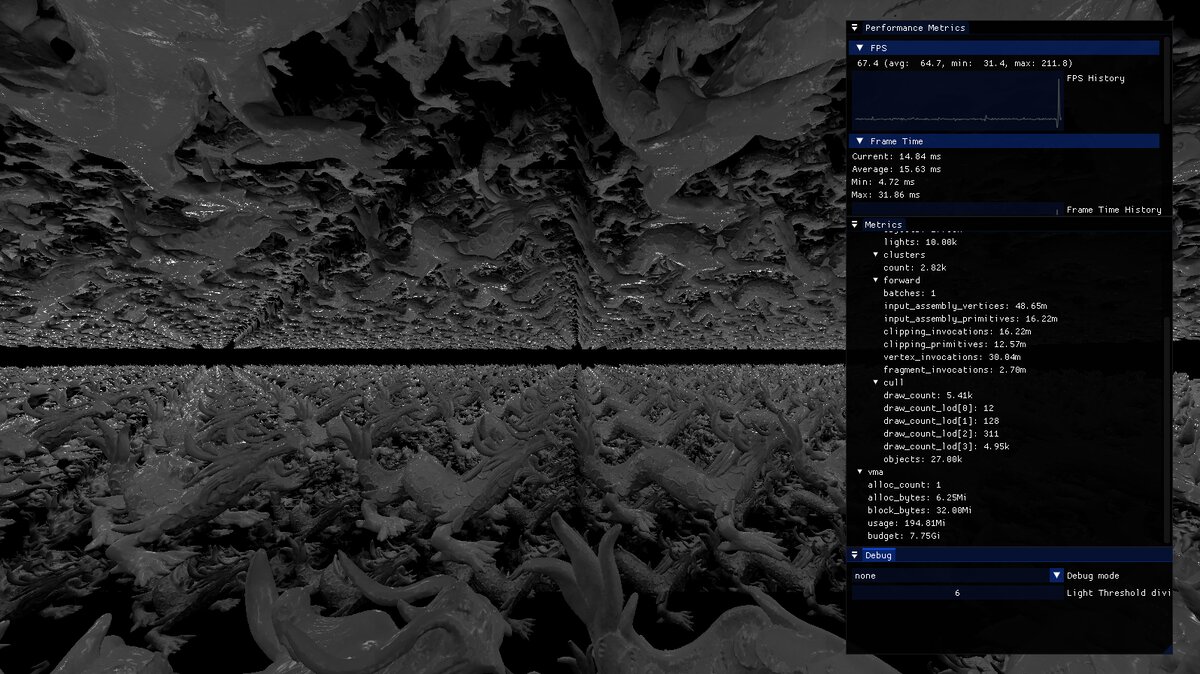
Below are some measurements where a single scene containing 27’000 Stanford dragons on an RTX A2000 12GB is rendered on 1080p. Overall, our metrics shows:
- All dragons are rendered in one batch
- About 5’000 are actually drawn
- Approximately 51 million input vertices and 17 million input triangles
- 30 million vertex invocations
- depending on direction, 2-6 million fragment invocations
While it seems weird comparing to a ‘conventional’ CPU renderer without showing how that was implemented, these measurements should be quite typical and are mostly here to show the contrast.
| Dragons | CPU-Driven w/o Culling | GPU-Driven + Culling | |||
|---|---|---|---|---|---|
| CPU | Draw | CPU | Draw | Cull | |
| 27'000 | 2.9ms | 22.2ms | 120.1μs | 30.7μs | 9.3ms |
Forward Clustered Shading
A classical forward renderer suffers from some issues, the biggest usually being overdraw. An overdrawn fragment is both wasted work, as well as inefficient usage of the GPU fill rate. As each fragment is being rendered in a forward-fashion, costly lighting calculation occurs for fragments which will not be seen. Historically, deferred rendering has been proposed to solve this. By rendering only albedo, normals and other properties per-object, and later shading by pixel, the shading is only performed on every visible fragment. While this solves overdraw, deferred shading comes with other issues relating to bandwidth as well as anti-aliasing.
The issue of overdraw can be handled in many ways, like performing an early depth-only pass or by triangle reordering. Here I focused on lessening the overdraw impact by reducing the cost of fragment shading. We will use what’s called Clustered Shading to reduce the cost of shading. In this case, it felt both interesting to try out an advanced technique, while also seeming to fit really well into the GPU-Driven structure we already have outlined. We are already bindless, and already keep the lights on the GPU, so why not?
Clustered shading is a method to reduce lighting calculations by reducing the number of lights that are tested against each fragment. The method works by splitting the view frustum into frustum shaped boxes called clusters (or froxels) and assigning the lights to the clusters based on their influence radius. When shading, each fragment can look up the containing cluster and only calculate shading using those lights. This means that clusters with no lights perform no lighting calculations.
The froxels are in reality skewed frustums, but will be simplified to AABBs in view space. While this is incorrect (some fragments end up in 2 clusters!), it makes the intersection calculations cheaper and is not a problem in reality.
Many design decisions were inspired by the Doom lectures @ SIGGRAPH (Rendering The Hellscape Of Doom Eternal and The Devil Is In The Details). Interestingly, they reuse the clustering method for other influence-volume systems like decals and light probes. I would love to dive deeper into this!
We will introduce 3 new buffers for clustering; Cluster Buffer, Cluster Items Buffer and the Light Buffer. The light buffer contains all the scenes point-lights (or can be expanded to all lights which has an influence volume). The cluster buffer contains the actual clusters, which will be a fixed set. The cluster items buffer is used as an indirection for the clusters reference to lights.
Similar to the object buffer, the light buffer is CPU accessible (writes come from CPU), so dynamic lights are supported.
Cluster Assignment
Assignment of lights to clusters is the complicated part of this system. After this pass, each cluster will have a reference to the start of the cluster items, as well as a hash and the number of lights. Each cluster supports up to 255 lights.
Assignment is done using a simple AABB-sphere intersection test. As the lights don’t store their radii, this needs to be calculated using the intensity and the falloff parameters. A simple naive implementation would be similar to how the Draw Buffer culling works. Let each invocation handle a single cluster, and then iterate over every lights directly. Each invocation reserves a range of cluster items using an atomic counter, and finally writes the indices. Using this naive approach, about 10′000 lights could be assigned to 2′800 clusters in 6ms on a GTX 1070. While an extreme case, there is room for improvement.
This method requires a lot of memory accesses (although they are mostly coherent), and repeats light radii calculations. Another issue is that the amount of memory required is very high, as there is no communication between clusters. Therefore, each cluster needs to reserve a worst-case amount of memory. If using a 16x8x24 grid, this would require 3.1MB of memory. Also consider that when looking up items during shading, a sparse lookup would occur in the items buffer.
We will again apply compaction, and carefully consider how the threads can cooperate. In this method, the cluster assignment is broken up into multiple stages; pre-fetching, intersection, and writing. The stages require explicit barriers to ensure that all invocations are in sync. The optimized approach uses light batches, with the same batch size as the size of the work group. First, each invocation collaborates on reading a single light of the following batch into shared memory. After this, the radii have been calculated for all lights. The intersection tests work as before, still using coherent reads, but from shared memory. Each invocation keeps a running hash of the light IDs that intersected, as well as store the lights into invocation-private memory. After there are no more batches to process, the invocations hashes are compared. If multiple invocations have the same hash, the one with the lowest ID writes the lights from private memory to the cluster list, and atomically increments the number of items in the list. This implementation is shown below.
Using this method, with full compaction, assigning 10’000 lights to 2’800 clusters took only 1.1ms and only requiring 164KB of cluster item memory!
| Naive | Collaborative | Full | |
|---|---|---|---|
| Time | 6ms | 1.3ms | 1.1ms |
| Memory | 3.1MB | 3.1MB | 164KB |
This method could be optimized further. As we do the pre-pass, the invocations could collaborate on culling lights to the entire frustum, reducing the amount of work required. While this is not implemented, it shouldn’t be too hard.
Below is the compute shader provided. It is really long and slightly confusing, but I thought it might help somebody looking to implement a similar system. Or you know, just interesting to see different parallelization strategies!
layout(local_size_x = 128) in;
shared vec4 shared_lights[128];
shared uint shared_hashes[128];
shared uint shared_starts[128];
shared uint shared_first_invocation_with_hash[128];
void main() {
uint cluster_index = gl_GlobalInvocationID.x;
uint cluster_item_count = 0;
uint cluster_item_offset = cluster_index * MAX_CLUSTER_ITEMS;
vec3 cluster_min;
vec3 cluster_max;
uint private_items[MAX_CLUSTER_ITEMS];
if (cluster_index_valid(cluster_index, cluster_constants)) {
cluster_min = clusters[cluster_index].bounds_min.xyz;
cluster_max = clusters[cluster_index].bounds_max.xyz;
}
uint hash = hash_fnv1a_init();
uint local_index = gl_LocalInvocationID.x;
for (uint batch_start = 0; batch_start <= highest_light; batch_start += 128) {
uint light_batch_count = min(128, highest_light + 1 - batch_start);
// Cooperatively cache this batch of lights and calculate their radii
// Here we can also perform an early cull if the light is outside the frustum.
barrier();
if (local_index < light_batch_count) {
uint light_id = batch_start + local_index;
LightData light = lights[light_id];
vec4 position_ws = light.position;
vec3 position = vec3(push.view * position_ws);
position *= -1;
float intensity = distance(light.color.rgb, vec3(0.0))
* light.color.a;
float radius = calculate_light_radius(
light.falloff_linear,
light.falloff_quadratic,
intensity
);
shared_lights[local_index] = vec4(position, radius);
}
barrier();
// Process this batch of lights
if (cluster_index_valid(cluster_index, cluster_constants)) {
for (uint i = 0; i < light_batch_count; i++) {
if (cluster_item_count >= MAX_CLUSTER_ITEMS) break;
uint light_id = batch_start + i;
vec4 packed = shared_lights[i];
if (sphere_aabb_intersect(packed.xyz, packed.w, cluster_min, cluster_max)) {
private_items[cluster_item_count] = light_id;
cluster_item_count++;
hash = hash_fnv1a_next(hash, light_id);
}
}
}
}
hash = hash_fnv1a_next(hash, cluster_item_count);
shared_hashes[local_index] = hash;
shared_first_invocation_with_hash[local_index] = 0xFFFFFFFF;
barrier();
if (!cluster_index_valid(cluster_index, cluster_constants)) return;
// scan the subgroup for the first thread with the same hash as us
for (uint i = 0; i < 128; i++) {
if (i > local_index) continue;
if (hash == shared_hashes[i]) {
atomicMin(shared_first_invocation_with_hash[local_index], i);
}
}
bool is_first = shared_first_invocation_with_hash[local_index] == local_index;
uint first = shared_first_invocation_with_hash[local_index];
if (is_first) {
uint start = atomicAdd(cluster_items_size, cluster_item_count);
shared_starts[local_index] = start;
for (uint i = 0; i < cluster_item_count; i++) {
cluster_items[start + i] = private_items[i];
}
}
barrier();
clusters[cluster_index].item_start = shared_starts[first];
clusters[cluster_index].hash_and_num_lights = cluter_hash_and_count(hash, cluster_item_count);
}
Go ahead, look at the images!



Cluster Shading
Finally, the cluster data can be used for shading. When shading a given fragment, we calculate the cluster index given the view-space fragment position. We can then iterate over each light in the cluster and shade the fragment using the lights.
Usually, multiple fragments in the same subgroup will be contained by the same cluster. This means that in theory, we should be able to optimize for this by sharing information within the subgroup. My solution uses ballots to determine if an entire subgroup is contained by the same cluster hash, and if so, reads the lights in a scalar fashion. This should mean that instead of performing vectorized reads and storing in VGPRs (vector general purpose registers), we can make memory accesses more coherent. The RDNA architecture has specialized scalar caches and optimized operations for VGPRs, meaning that this should be faster. However, this has a negative performance impact on NVIDIA GPUs. It is not that much slower, but might want to toggle this on or off depending on architecture. It could also be that my implementation of this is wrong, but I have no way of testing it on RDNA :)
Scalar reads are shown as green in the figure below.

Finally, the fragment shader looks something like this:
void main() {
...
uint cluster_id = cluster_lookup(position_vs, cluster_constants);
uint cluster_hash;
uint cluster_num_lights;
cluster_unpack_hash_and_count(clusters[cluster_id].hash_and_num_lights, cluster_hash, cluster_num_lights);
PbrProperties props = PbrProperties(
albedo,
roughness,
metallic);
// if entire subgroup in the same cluster, we can read only once
bool subgroup_same_hash = subgroupAllEqual(cluster_hash);
if (subgroup_same_hash) {
uint group_cluster_id = subgroupBroadcastFirst(cluster_id);
uint group_num_lights = subgroupBroadcastFirst(cluster_num_lights);
uint first_cluster_item = clusters[group_cluster_id].item_start;
uint last_cluster_item = first_cluster_item + group_num_lights;
for (uint i = first_cluster_item; i < last_cluster_item; i++) {
uint cluster_item = cluster_items[i];
uint light_id = cluster_item;
LightData light = lights[light_id];
color += point_light_shade(P, N, V, light, props);
}
} else {
for (uint i = 0; i < cluster_num_lights; i++) {
uint cluster_item = cluster_items[clusters[cluster_id].item_start + i];
uint light_id = cluster_item;
LightData light = lights[light_id];
color += point_light_shade(P, N, V, light, props);
}
}
outColor = vec4(color, 1.0);
}
Results
Okay, so lets be honest. 27’000 dragons and 10’000 lights is possible, but just barely. It requires lowering the influence radius of lights to 1⁄6 of their power. In this scene it visibly causes artifacts. Specifically, when there are many lights densely packed, each light contributing 1% still means that they together contribute 10’000%! The performance and the required constants really depends on the scene. It is an unreasonable scene to begin with. In the second image, you can better see the dynamic range (but sadly not the thousands of dragons).
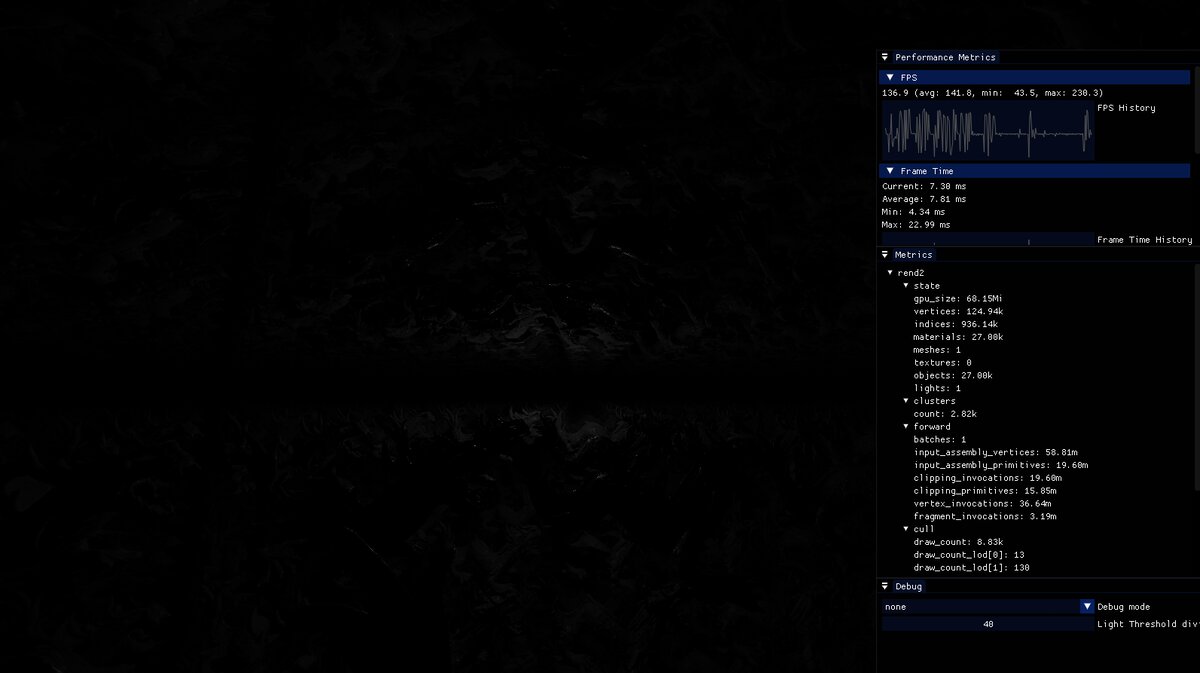
Unlit
That was everything I had to share today. I hope this can help spark some ideas of your own about parallelization! There are many other tricks for optimization (meshlet rendering, occlusion culling, etc.) which all could improve performance, and can be built on top of this architecture. I would love to investigate further, but I am sadly out of time (for now).
Feel free to send me an email (olle at logdahl dot net) if you find any issues, or if you have ideas on how to outperform this! ;)